2.1 지도학습과 비지도학습
📌 우리가 배웠던 회귀와 분류는 대표적인 지도학습이라고 했습니다. 지도학습은 문제(X)와 정답(Y)가 주어지고 문제(X)가 주어졌을때 정답(Y)을 맞추는 학습이였어요.
반면 비지도 학습이란 답(Y)을 알려주지 않고 데이터 간 유사성을 이용해서 답(Y)을 지정하는 방법 입니다.
- 머신러닝 개요
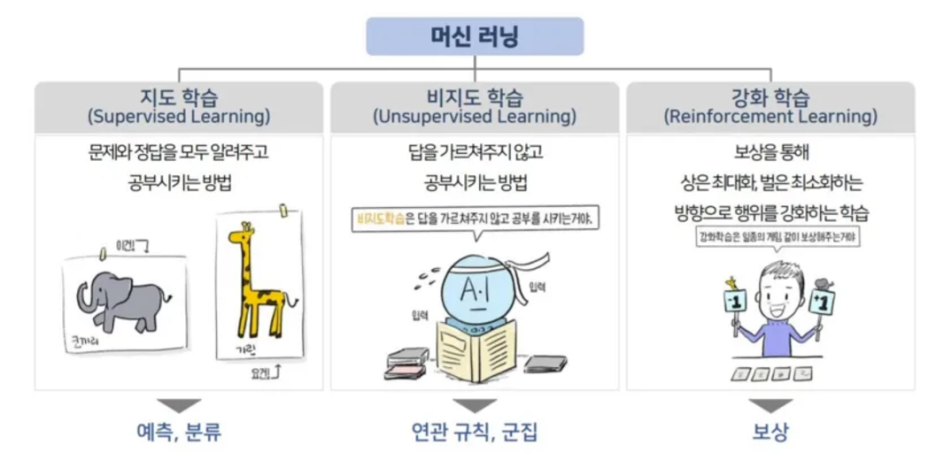
사진 설명을 입력하세요.
- 비지도 학습 예시
- 고객 특성에 따른 그룹화
- ex) 헤비유저, 일반유저
- 구매 내역별로 데이터 그룹화
- ex) 생필품 구매
📌 다시 말해 비지도 학습은 데이터를 기반으로 레이블링을 하는 작업이라고 하겠습니다. 정답이 없는 문제이기 때문에 지도 학습보다 조금 어렵고 주관적인 판단이 개입하게 됩니다.
3. 비지도 학습
✔️ 대표적인 비지도 학습인 K-평균 알고리즘을 알아봅시다.
3.1 붓꽃 데이터를 이용한 군집화 예시
📌 K - 평균 군집화 혹은 알고리즘(K-means clustering)은 가장 일반적으로 사용되는 알고리즘입니다. 쉬운 예시를 위해서 붓꽃 데이터(iris)데이터로 살펴보겠습니다.
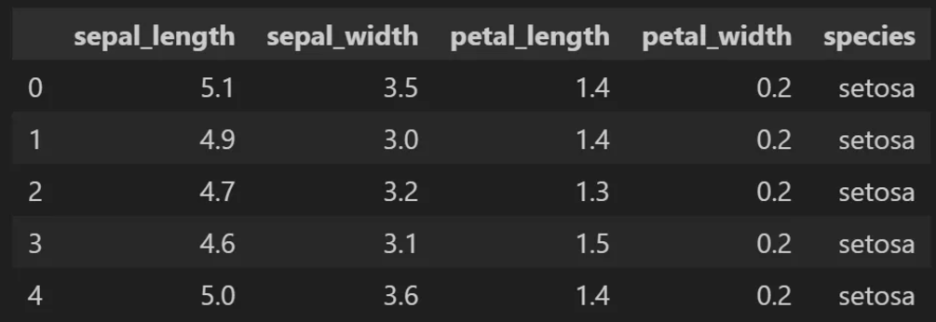
사진 설명을 입력하세요.
- sepal_length: 꽃 받침의 길이
- sepal_width: 꽃 받침의 너비
- petal_length: 꽃 잎의 길이
- petal_width 꽃 잎의 너비
- species(Y, 레이블): 붓꽃 종(setosa, virginica, versicolor)
📌 꽃 에 대한 정보(X)로 종, Species(Y)를 맞추는 문제를 푼다면 지도 학습이라고 합니다. 반면, Species가 없다면? 정보에 따라서 데이터를 분류해볼 수 있지 않을까요?꽃
- Labeling이 안된 꽃 받침 길이-너비 산점도
📌 위 점을 적당히 그룹화 해볼까요. 2개로도 3개로도 등등 다양한 방법이 있을 수 있
- Labeling이 된 꽃 받침 길이 - 너비 산점도
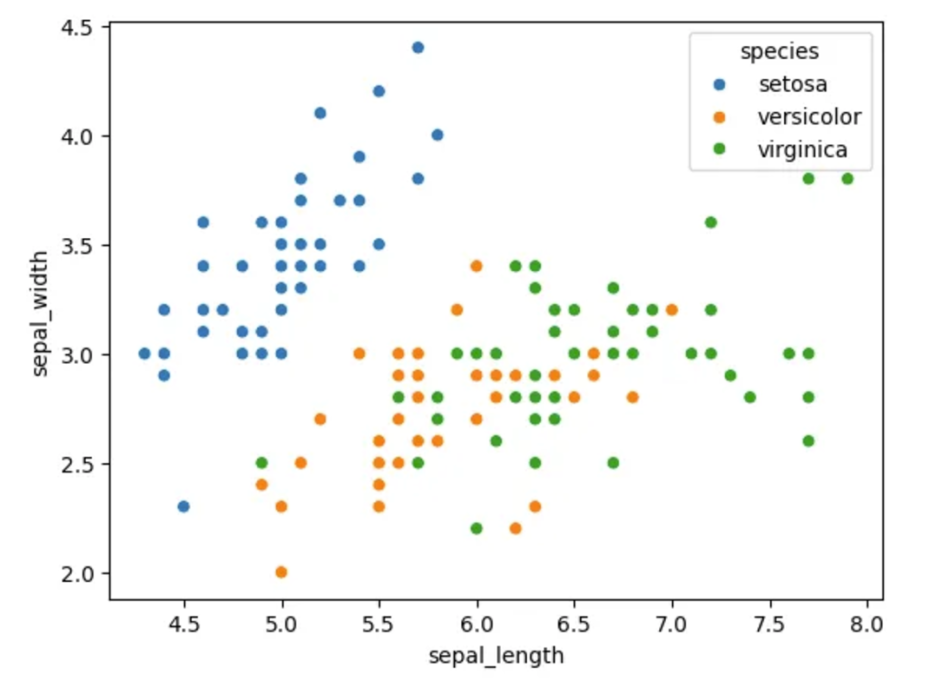
사진 설명을 입력하세요.
📌 실제 데이터는 위와 같이 표기 되었어요. 이렇게 3개로 분류된 건 학자들의 나름의 기준으로 정의했기 때문입니다. “데이터”의 기준으로 보면 3개가 아닌 K개의 그룹으로 정해볼 수 있을 거예요.
- (스포) K means를 이용한 군집화
3.2 K-Means Clustering 이론
☑️ K-Means Clustering 수행 순서
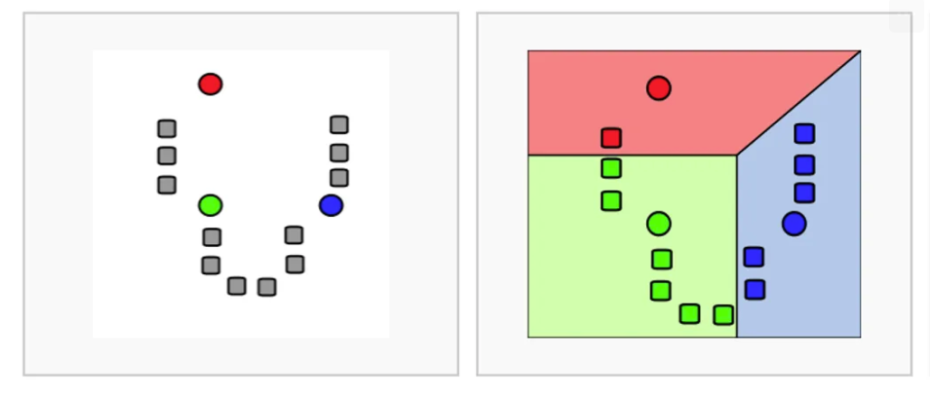
사진 설명을 입력하세요.
- K개 군집 수 설정
- 임의의 중심을 선정
- 해당 중심점과 거리가 가까운 데이터를 그룹화
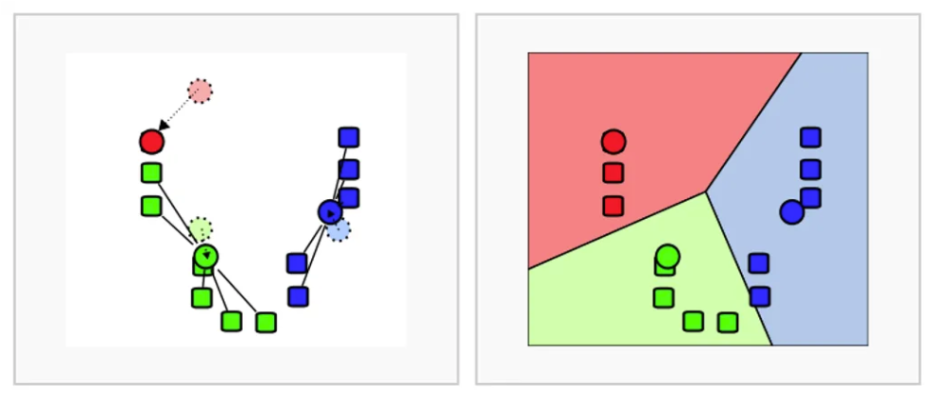
사진 설명을 입력하세요.
- 데이터의 그룹의 무게 중심으로 중심점을 이동
- 중심점을 이동했기 때문에 다시 거리가 가까운 데이터를 그룹화 (3~5번 반복)
📌 이렇게 임의로 분석가가 선정한 K군집 수(위 그림에서는 3)를 기준으로 데이터 군집화 프로세스를 진행 한답니다.
- 장점
- 일반적이고 적용하기 쉬움
- 단점
- 거리 기반으로 가까움을 측정하기 때문에 차원이 많을 수록 정확도가 떨어짐
- 반복 횟수가 많을 수록 시간이 느려짐
- 몇 개의 군집(K)을 선정할지 주관적임
- 평균을 이용하기 때문에(중심점) 이상치에 취약함
- Python 라이브러리
- sklearn.cluster.KMeans
- 함수 입력 값
- n_cluster: 군집화 갯수
- max_iter: 최대 반복 횟수
- 메소드
- labels_: 각 데이터 포인트가 속한 군집 중심점 레이블
- cluster_centers: 각 군집 중심점의 좌표
3.3 군집평가 지표
☑️ 실루엣 계수
📌 비지도 학습 특성 상 답이 없이 때문에 그 평가를 하긴 쉽지 않습니다. 다만, 군집화가 잘되어 있다는 것은 다른 군집간의 거리는 떨어져 있고 동일한 군집끼리는 가까이 있다는 것을 의미합니다.
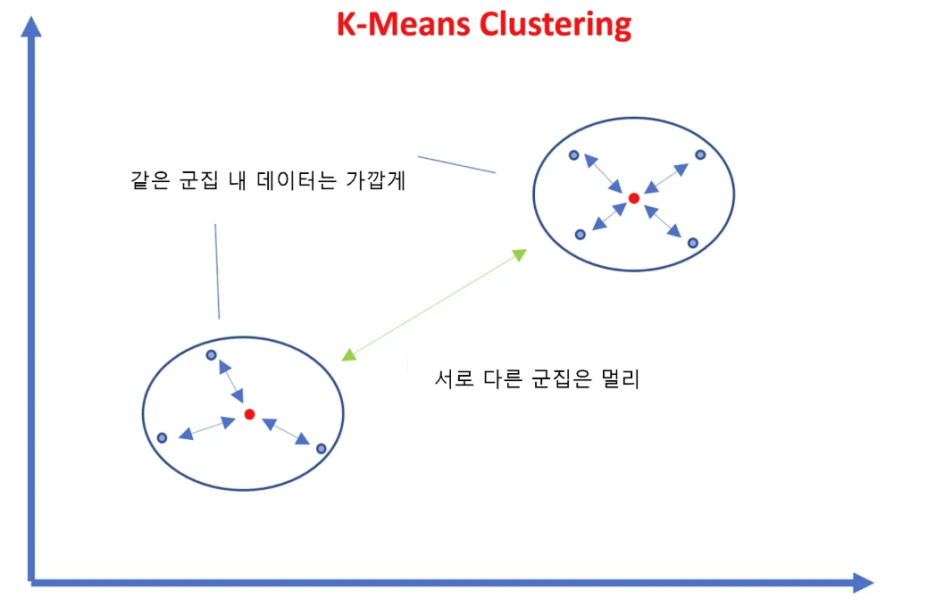
사진 설명을 입력하세요.
📌 이를 정량화 하기 위해 **실루엣 분석(silhouette analysis)**이란 간 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 측정합니다. 수식은 다음과 같지만 그냥 이해만 해보세요!
- 실루엣 계수
- 수식:
- $$ S(i) = \frac{b(i)-a(i)}{max(a(i),b(i))} \ 단\ i는 데이터 $$
- $a(i)$ : 데이터 포인트 $i$ 과 같은 군집에 속한 다른 포인트들과의 평균 거리
- $b(i)$ : 데이터 포인트 $i$ 와 가장 가까운 다른 군집 간의 평균 거리
- 해석: 1로 갈수록 잘 군집화 되어 있음. -1에 가까울수록 잘 못 군집화 되어 있음.
📌 수식을 해석해보자면 특정한 데이터 i의 실루엣 계수는 얼마나 떨어져있는가($b(i) -a(i)$)가 클 수록 크며, 이를 단위 정규화를 위해 $a(i), b(i)$ 값 중에 큰 값으로 나눕니다.
- 좋은 군집화의 조건
- 실루엣 값이 높을수록(1에 가까움)
- 개별 군집의 평균 값의 편차가 크지 않아야 함
- Python 라이브러리
- sklearn.metrics.sihouette_score: 전제 데이터의 실루엣 계수 평균 값 반환
- 함수 입력 값
- X: 데이터 세트
- labels: 레이블
- metrics: 측정 기준 기본은 euclidean
3.4 (실습) 붓꽃 데이터를 이용한 군집화
✅ 붓꽃 데이터를 이용한 실습을 해봅시다.
- 붓꽃데이터 load
- Kmeans Clustering
- 시각화 결과 비교
- 군집화 평가
3.3 (실습) 고객 세그멘테이션
✅ 비지도 학습을 배웠으니 실제 업무에 적용해봅시다
☑️ 고객 세그멘테이션의 정의
📌 비지도 학습이 가장 많이 사용되는 분야는 고객 관계 관리(Customer Relationship Management, CRM)분야 입니다. 이중 고객 세그멘테이션(Customer Segmentation)은 다양한 기준으로 고객을 분류하는 기법입니다. 주로 타겟 마케팅이라 불리는 고객 특서엥 맞게 세분화 하여 유형에 따라 맞춤형 마게팅이나 서비스를 제공하는 것을 목표로 둡니다.
사진 설명을 입력하세요.
- RFM의 개념
- Recency(R) 가장 최근 구입 일에서 오늘까지의 시간
- Frequency(F): 상품 구매 횟수
- Monetary value(M): 총 구매 금액
☑️ (실습) 고객 세그멘테이션
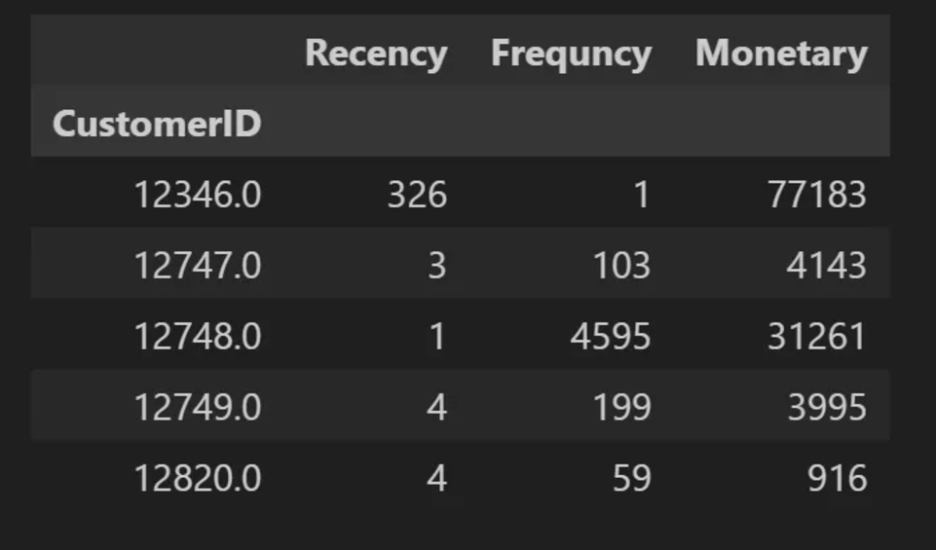
사진 설명을 입력하세요.
- UCI 데이터 세트 다운로드 링크
- retail_df.head()
- retail_df.info()

사진 설명을 입력하세요.
- 컬럼 정보
- InvoiceNO: 6자리의 주문번호(취소된 주문은 c 로 시작)
- StockCode: 5자리의 제품 코드
- Description : 제품 이름(설명)
- Quantity: 주문 수량
- InvoiceDate: 주문 일자, 날짜 자료형
- UnitPrice: 제품 단가
- CustomerID: 5자리의 고객 번호
- Country: 국가명
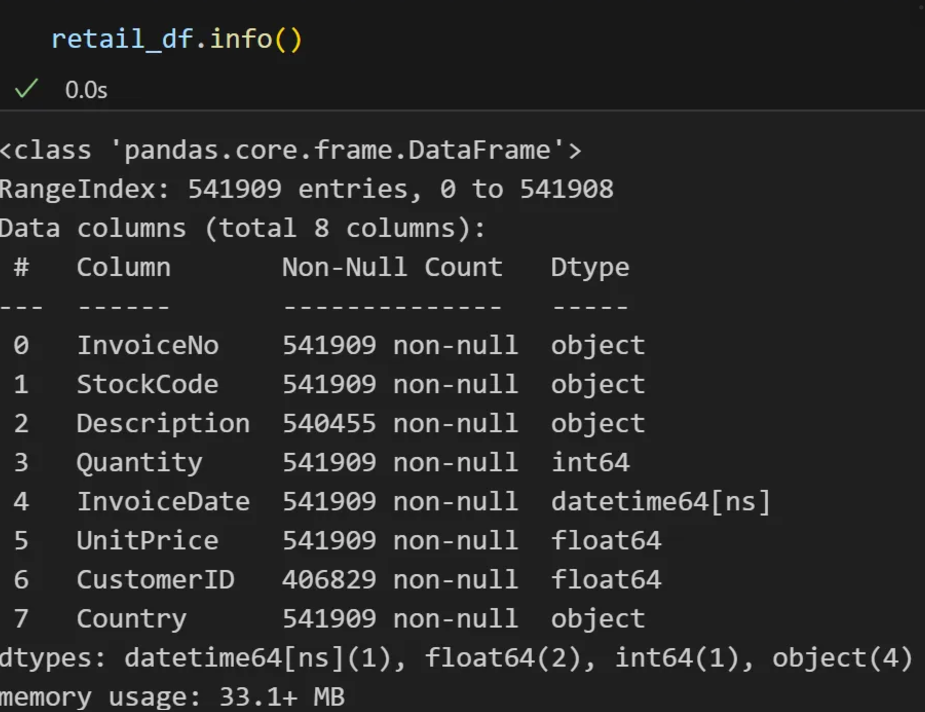
사진 설명을 입력하세요.
- EDA
- 데이터전처리
- customerID 결측치 삭제
- InvoiceNo, UniPrice, Quantity 데이터확인 및 삭제
- 영국데이터만 취함
- RFM 기반 데이터 가공
- 날짜 데이터 가공
- 최종목표
- StandardScaler 적용
- 고객 세그멘테이션
- 평가
4.2 데이터 직군별 머신러닝 활용 방안
📌 그럼 이렇게 배운 머신러닝을 각 직군은 어떻게 써먹을 수 있을까요? 직군에 대한 간략한 설명과 머신러닝 적용방안은 다음과 같습니다.
- Data Engineer
- 역할
- 데이터 Extract(추출), transform(변환), Load(적재) 및 데이터 파이프라인 관리
- Workflow 과정 자동화
- ML/DL 활용 낮음
- Machine Learning Engineer
- 역할
- 데이터를 기반으로 모델 최적화
- 개발한 모델을 실제 운영에 배포, 성능 평가, 유지 보수
- ML/DL 활용 필수
- AI Researcher
- 역할
- 머신러닝/딥러닝 모델을 논문을 통해 읽고 구현
- 논문 작성 및 발표
- ML/DL 활용 필수
- Data Analyst
- 역할
- 데이터 분석 및 인사이트 도출
- 보고서 작성 및 데이터 시각화
- ex) A/B test, 유저분석을 통해서 PM/PO/대표를 보고&설득
- ML/DL 활용 중간: 고객 세분화(클러스터링), 고객 이탈 분석(판매량 예측), 텍스트 분석(자연어 처리를 이용한 리뷰 분석)